一、字典
一个字典的声明:

字典中的参数有二:键(key)和键值(value)。在上图中,“CA"是键,“California"是键值。
1、字典的操作
下面是一些操作字典的例子和方法:
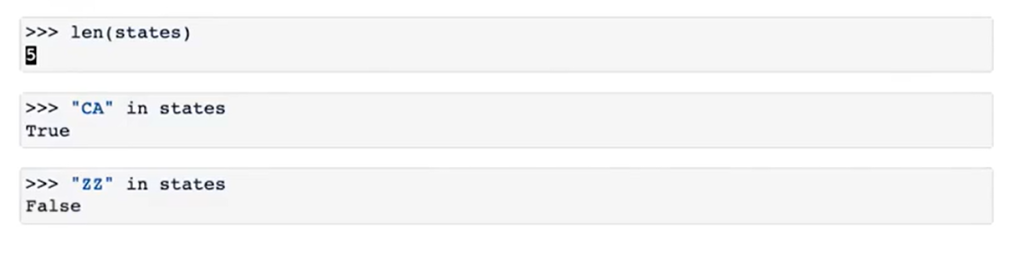
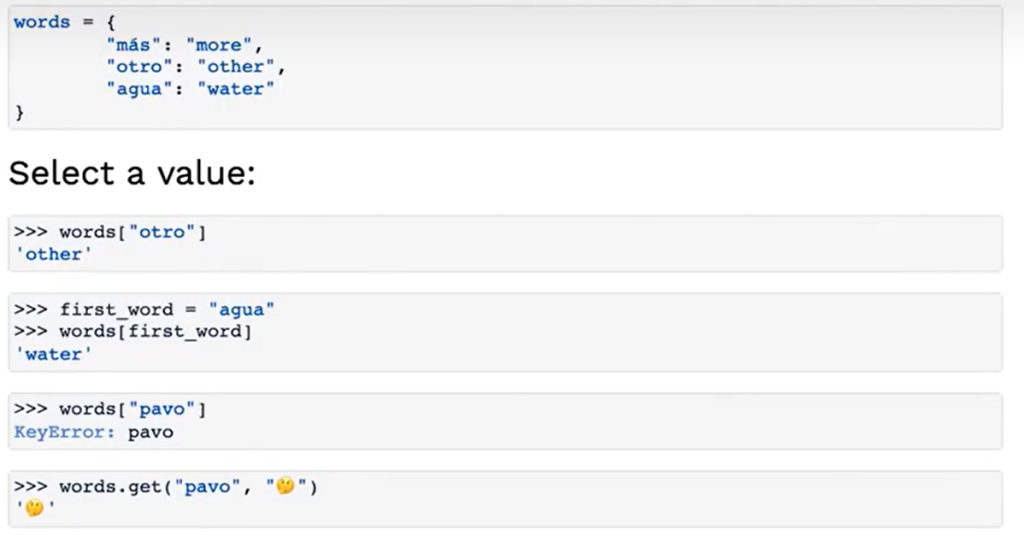
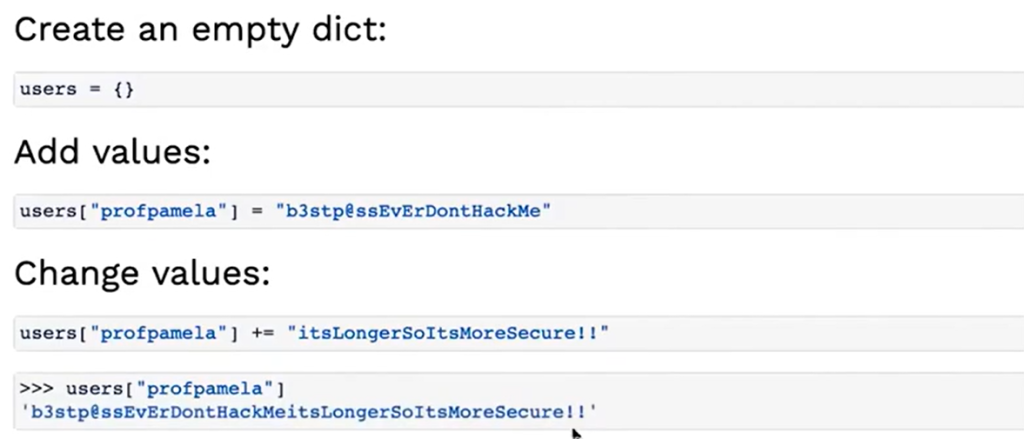
2、字典的特性
- ①不存在多个相同的键

会输出'a': 'agua"
②键的引用必须是一个常量。例如:数字、字符串。
③键值的引用可以是任意种类。例如:

在字典中引用了字典
3、字典的迭代
一个简单的字典迭代如下图
这个迭代返回的是字典中的键,我们再在之后的代码中根据键来索引键值。
那么问题来了,索引到的键的排列顺序是怎样的呢?
答案是按照键的插入先后来排序。
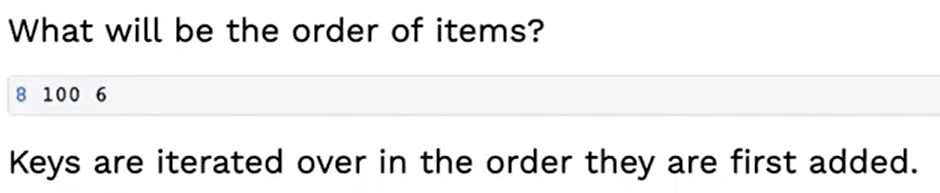
也就是说,在python3中,目前我们没有办法“获取某字典中第n个键值”。当我们需要这个功能时,应该考虑使用列表。
二、复合数据结构
1、一些可能的复合数据结构

2、构建矩阵(martix)
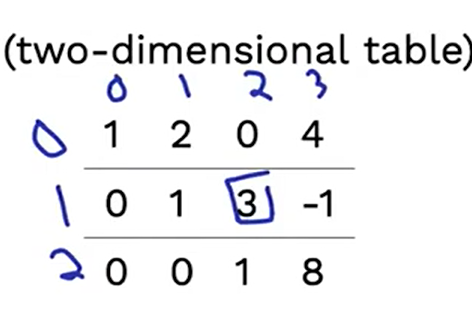
一种可能的矩阵表示
一种构建方式是使用列表+列表。

行主序的矩阵表示
- 这行代码是很有意思的,值得认真体会
| |

列主序的矩阵表示
值得注意的是,无论你采用的是行主序还是列主序,使用你程序的人都不会知道这个细节。
“程序员可以有自己的观点。我们可以用我们的观点来指导我们的实现,只需要为使用这个功能的人提供一个好的抽象。”
3、构建树
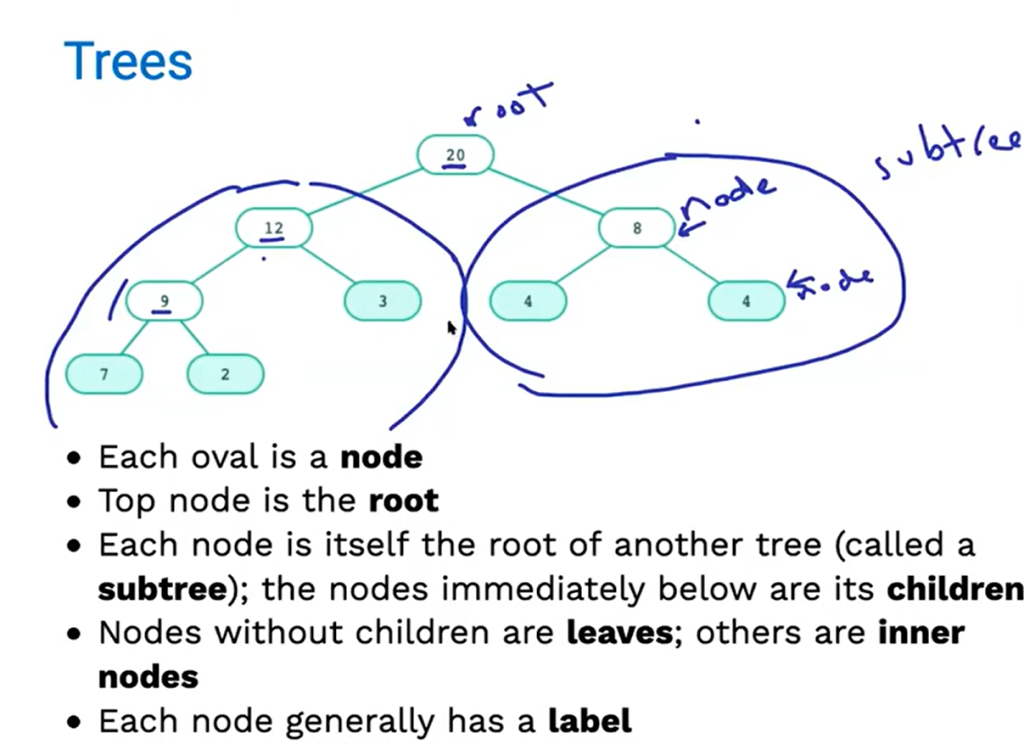
树的定义
这一次,我们需要实现下面四种抽象封装:


列表+列表构建树

元组+列表构建树,这个看起来舒服多了!
4、树与递归
从上述的代码和表述中不难看出,树是一种递归结构。(我们也学过树递归)当我们需要递归时就可以用到它。

尝试写一个函数,输入一个树,返回该树的叶节点数量,可以有如下代码:

从中我们可以窥见树递归的几个关键特性:
①边界情况往往是递归到叶结点,因为此时已经”无路可走“;
②进行下一步递归,只需要对子节点执行函数即可,用for很方便。
可以发现,我们构建出的树结构其实是一种非常便于递归的数据结构。
破坏与非破坏性函数
尝试写一个函数,输入一个树,将该树的每个节点的标签都翻倍。可以有如下代码:

也可以将其简化成下面的代码:

如果没有children就不会触发下一次double函数,故不会无限递归
在这个过程中,我们实际上新建了一棵树来返回,并没有破坏原来的树。我们将这种操作理解成“非破坏性”的。
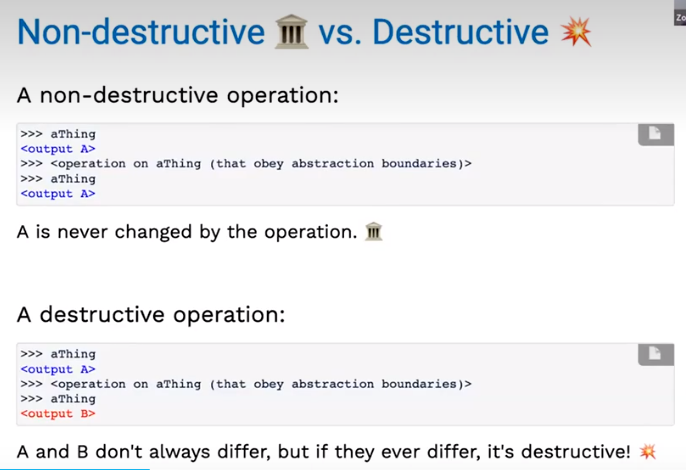
类似的,变量也有可变和不可变之分:
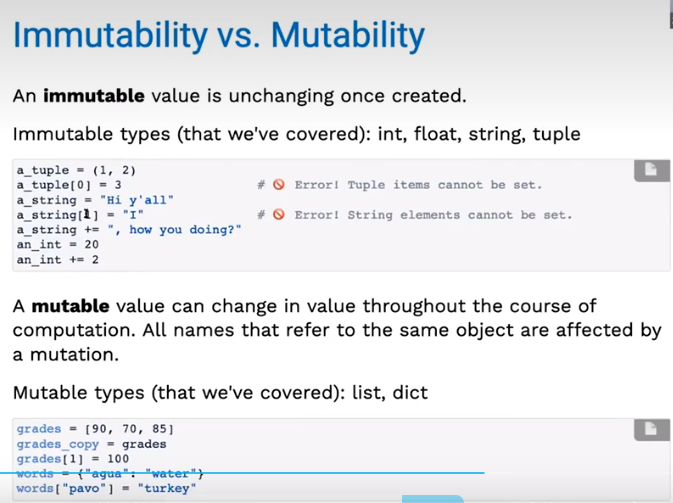
我们之前所的构建树操作和数据结构可以看作是非破坏性和不可变类型。我们也可以将其改变,比如将数据结构改为List嵌套List,就可以实现破坏性地操作树和构建树。
在对List的操作中,我们也可以见到一些破坏性/非破坏性的操作。值得注意的是非破坏性的操作会改变对内存的指向和引用,而破坏性的操作会直接修改原链表的内存本身。
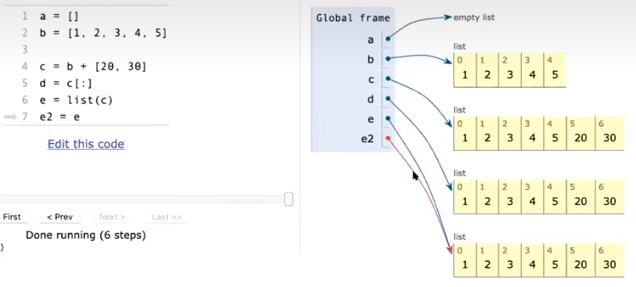
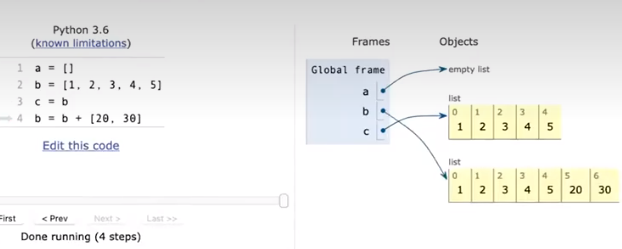
值得注意的是,这样操作会使b指向新的链表,但是+=不会,+=在链表中不是语法糖
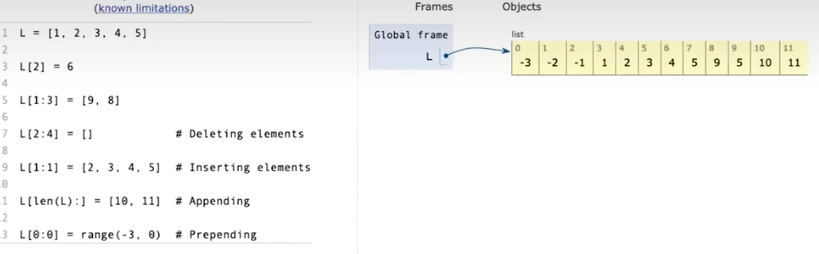
切片操作是破坏性的
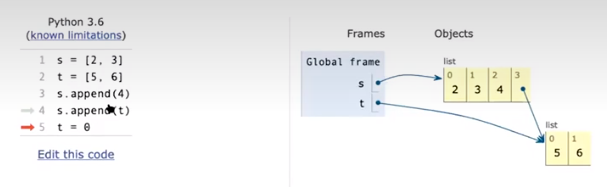
使用method来操作链表,破坏性
相等(Equality)和同一(Identity)

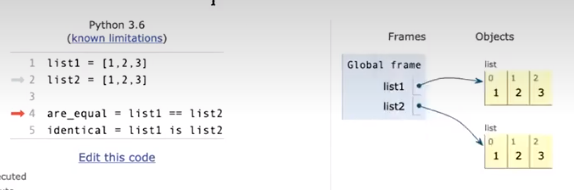
也就是说,同一代表了两对象完全相同,相等只代表了两对象的值相同。
我们可以用is 和 == 来分别判断同一和相等。一般来说,我们会在判断变量类型的时候使用is。其他时候,用is来代替==是比较危险的操作。
明显地,如果is返回True,那么==也会返回True。
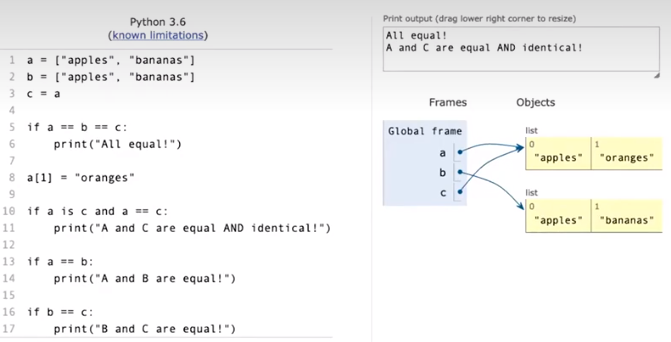
也可以写成这样的语法糖
作用域(Scoop)
看看下面的例子:
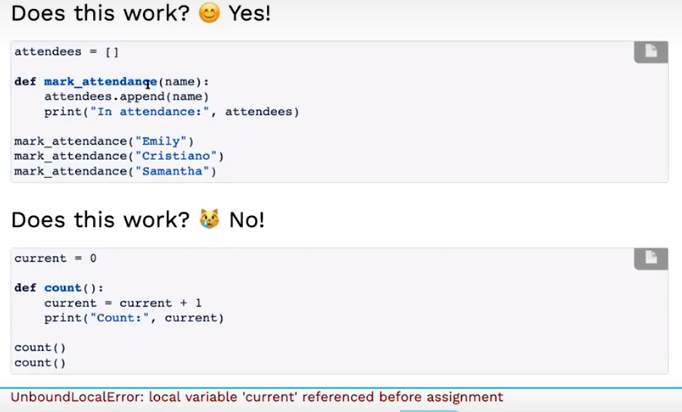
在第一个例子中,我们只是修改了链表对象,并没有进行赋值操作;在第二个例子中,我们实际上是在局部先定义了一个current变量,然后再进行current++,而这个全局变量还未被赋值就被引用,这就会引发UnboundLocalError。
解决这个问题的一个方法是添加global语句。这样在python执行到“current=”的赋值操作时,就会自动使用全局变量中的current,而不是在本地新建一个current变量。
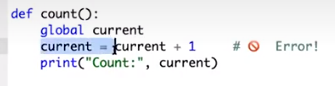
对于高阶函数,我们可以写nonlocal来查找并使用父框架的变量。

我们应该尽量避免写global和nonlocal,因为这会使抽象函数充满不确定性,代码中的某个全局变量也很有可能在不经意间被修改。我们只需要将某个全局变量作为参数传入函数就好了。
Fun fact
1

2
3